点评文章:
这篇文章有些标题党,但是文章内容本身是很值得一读的
- 用一个简单的例子,介绍了permutation test检验方法和bootstrap总体参数估计方法。这两个方法是在实际研究中很好用的方法,是我觉得这篇文章最有价值的地方。
- 介绍显著性缺陷:随意性、虚假确定感、忽略风险
- 提出实用替代方案: 文章没有止步于批判,而是提出了一个基于经济影响和风险管理的决策框架。利用自助法的输出(结果的分布)来量化潜在的收益和损失及其发生的概率,这为决策者提供了比单一的显著性判断丰富得多的信息。当然这个是用于经济量化和风险评估的方案,在生物科研中不太能用得上。但是其思路是可以借鉴的,不应该仅仅只看p值和置信区间,应该去挖掘背后更有意义的信息。
原文:Why “Statistical Significance” Is Pointless | by Samuele Mazzanti
代码:tds_why_statistical_significance_is_pointless
全文翻译:by Achuan-2
数据科学家的工作核心是决策制定。我们的工作聚焦于如何在不确定性下做出明智的选择。
然而,当涉及到量化这种不确定性时,我们往往依赖于"统计显著性"这一概念——这个工具,充其量只能提供浅层次的理解。
在本文中,我们将探讨为什么"统计显著性"是有缺陷的:武断的阈值、虚假的确定感以及无法解决现实世界中的权衡问题。
最重要的是,我们将学习如何超越显著与非显著的二元思维模式,采用一种基于经济影响和风险管理的决策框架。
1. 从一个例子开始
想象一下,我们刚刚进行了一次A/B测试,评估一个旨在提升用户网站停留时间——从而增加消费的新功能。
对照组包含5,000名用户,测试组包含另外5,000名用户。这给我们提供了两个数组,分别命名为treatment和control,每个数组包含5,000个值,代表各自组别中个体用户的消费情况。
首先最自然的做法是比较两个组别之间的平均消费。
1 | np.mean(control) # 结果:10.00 |
对照组显示平均消费为10.00美元,而测试组平均为10.49美元——增长了5%!听起来很有希望,不是吗?
但接着就会出现这个著名的问题:
这个结果具有统计显著性吗?
在这一点上,任何数据科学家都可能会转向"统计显著性"神话的两大支柱:
- p值,以及
- 置信区间。
让我们分别来看。
2. P值
p值解答的问题是:
如果两组之间没有真正的差异,我们观察到这么极端的结果的可能性有多大?
换句话说,我们暂时假设测试组和对照组之间没有真正的差异。然后,我们测试所观察到的结果是否过于极端,以至于不能归因于随机变异——这是一种反证法。
如果我们假设测试组和对照组没有区别,这意味着它们只是从同一底层分布中随机提取的两个样本。所以我们能获得的那个分布的最佳代表就是将它们合并成一个单一数组(我们称这个新数组为combined)。
1 | combined = np.concatenate([treatment, control]) |
现在,在这一点上,我们可以打乱这个新数组并将其分成新的测试组和对照组。
这就像免费运行一次新实验。与我们实际的A/B测试唯一的区别是,现在我们确切地知道测试组和对照组之间没有差异。
这被称为Permutation test “置换检验”。我们可以免费运行这个新实验,而且可以运行任意多次。这就是它的美妙之处。让我们重复这个过程,比如10,000次:
1 | permutation_results = [] |
这相当于运行了10,000次"虚拟"实验,并且我们知道测试组和对照组来自同一分布。
让我们绘制一个直方图来查看这10,000次实验的结果:
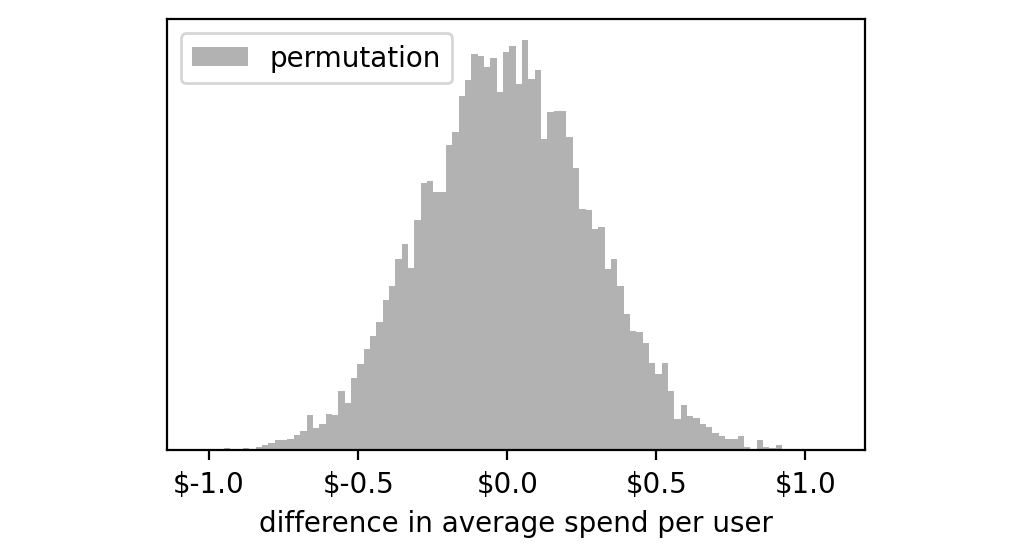
这些实验的分布似乎集中在零附近。这很合理,因为我们知道这些对照组和测试组是从同一数组中随机选择的,所以大多数情况下,它们平均值之间的差异会非常接近零。
然而,仅仅由于纯粹的偶然,有些极端情况下我们会得到较大的负数或正数:从-1美元到+1美元。
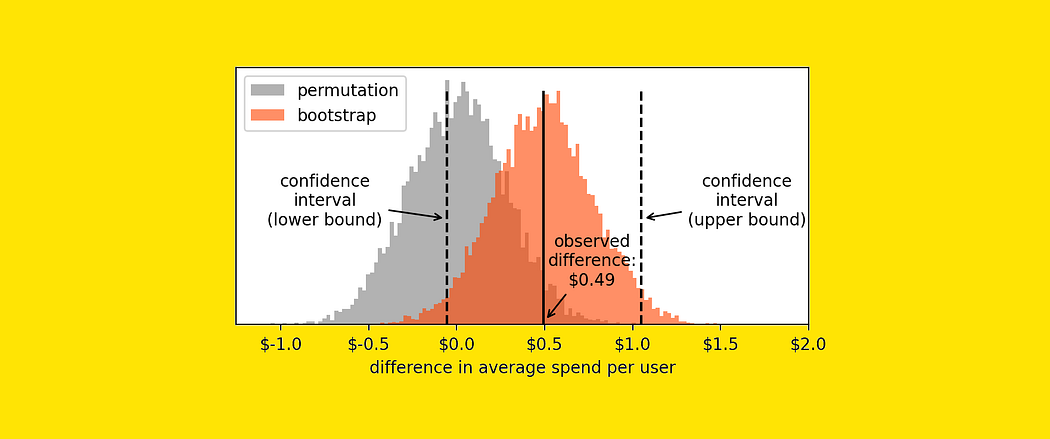
在这种情况下,获得一个像我们得到的那样极端的结果(0.49美元)的可能性有多大?要回答这个问题,我们只需计算结果高于0.49美元的实验的百分比。
1 | np.mean(np.array(permutation_results) >= 0.49) # 结果:0.04 |
4%的虚拟实验的结果高于+0.49美元。
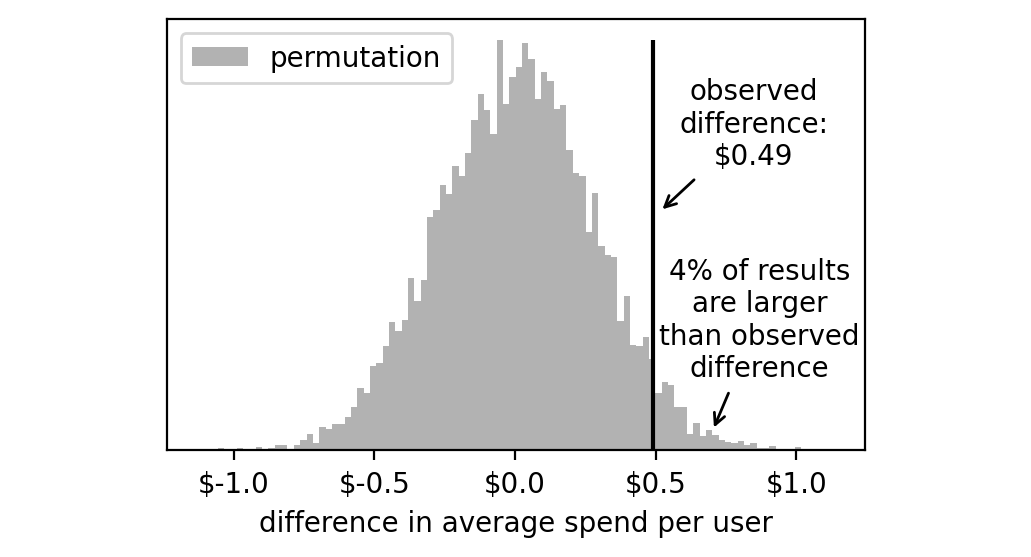
我们需要将这个数字翻倍,因为我们实际实验的结果可能在这个直方图的左侧或右侧尾部。因此,我们得到8%。
这就是我们要找的数字:我们的p值是8%。
这个值高吗?还是低?
几十年来在统计学中使用的完全武断的经验法则说我们应该使用5%作为阈值。如果我们的p值低于5%,那么我们可以得出结论,+0.49美元过于极端,不可能只是随机导致的(因此,具有统计显著性)。否则,我们可以得出结论,这个数字可能只是偶然造成的(因此,不具有统计显著性)。
由于在这种情况下,p值为8%,我们会得出结论认为我们观察到的差异(0.49美元)不具有统计显著性。
现在让我们看看第二个工具,置信区间是如何工作的。
3. 置信区间
我们用来计算p值的方法从假设测试组和对照组之间没有任何差异开始。置信区间则采取相反的方法。
我们假设我们观察到的测试组和对照组的分布确实代表了各自真实分布。
所以,就像我们之前做的那样,我们将通过从原始数据中抽样新的测试组和对照组来运行大量"虚拟实验"。
重要的区别是,我们现在将为每个组别分别抽取这些样本:新的测试样本将从原始测试组中提取,新的对照样本将从原始对照组中提取。
这意味着现在我们不能只是打乱样本,因为如果那样做,每个组的平均值就不会改变!
这里真正巧妙的技巧是进行有放回抽样。这模拟了从原始人群中抽取新的独立样本的过程,同时每次都给我们提供不同的样本。
这种算法被称为自助法(bootstrapping)。
让我们再运行10,000次虚拟实验:
1 | bootstrap_results = [] |
解释:有放回抽样,会产生重复样本
2
3
4
>>>> control = np.array([1,2,3,4,5])
>>>> np.random.choice(control, size=len(control), replace=True)
array([2, 4, 2, 1, 5])
所以现在我们在名为bootstrap_results的列表中有10,000次虚拟实验。我们可以绘制这些值的直方图。出于好奇,让我们将它与之前包含permutation test实验结果的直方图一起绘制。
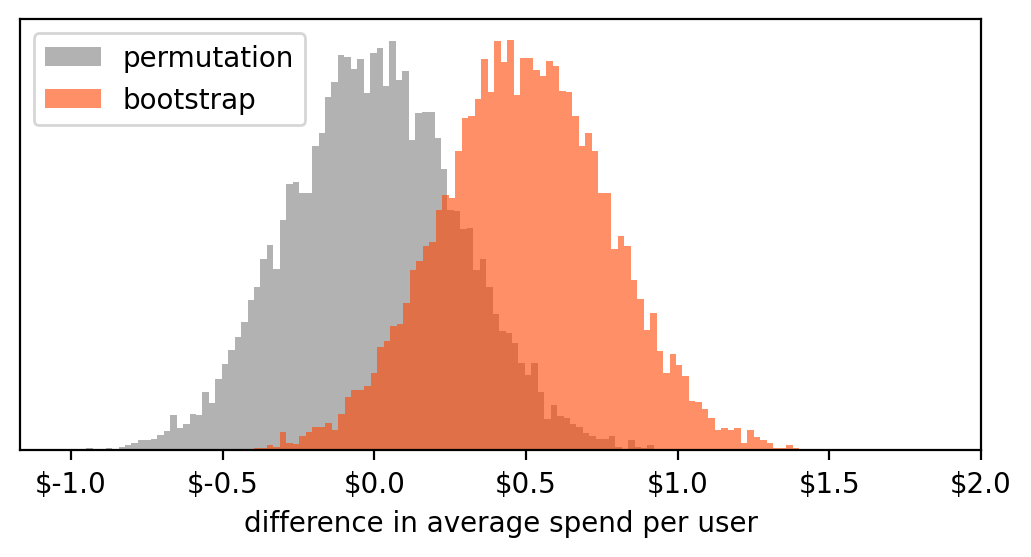
这两个直方图告诉我们两个不同的事情:
- Permutation test:10,000次虚拟测试的结果,假设我们观察到的测试组和对照组来自同一人群。因此,任何测量的差异都只是由于偶然。
- bootstrap:10,000次虚拟测试的结果,假设测试组和对照组的分布就是我们观察到的。因此,这些值近似我们测量中的变异性并量化其不确定性。
现在,要计算置信区间,我们只需从直方图中取两个点,使得2.5%的值在左侧,2.5%的值在右侧。
这很容易用numpy的percentile函数来完成。
1 | lower_bound = np.percentile(bootstrap_results, 2.50) # 结果:-0.0564 |
这是区间边界与自助法直方图相比的位置:
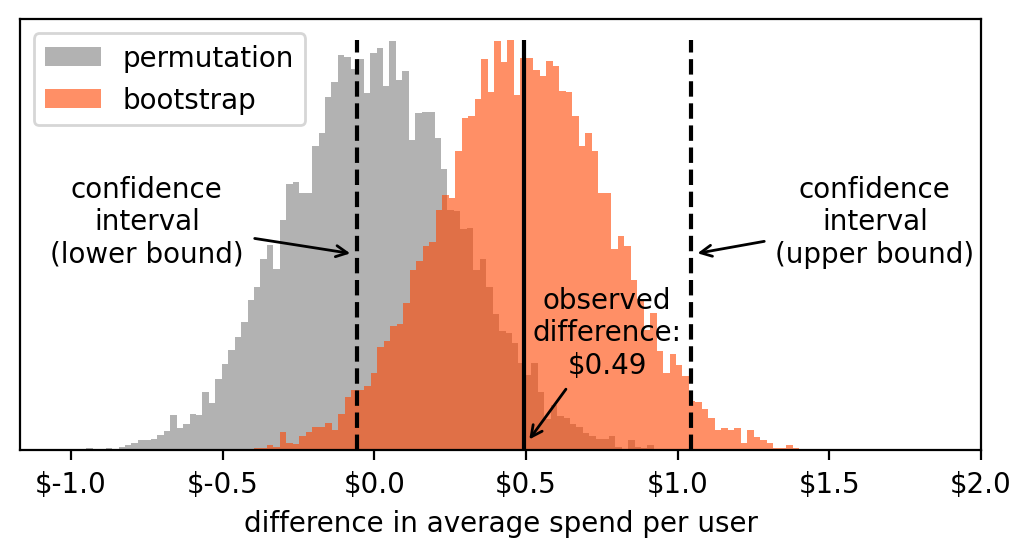
由于置信区间包含零,我们必须得出结论,我们的结果不具有统计显著性(即与零没有显著差异)。
这是有道理的,因为它与我们从p值推导出的信息是一致的。
4. 那么"统计显著性"有什么问题?
如果你有一种感觉,觉得确定统计显著性的整个过程有些不对劲——我完全同意。
统计显著性的概念有缺陷,原因如下:
- 它非常武断。
- 它给人一种虚假的确定感。
- 它没有考虑风险规避。
让我解释一下。
- 它非常武断。通常用来决定显著性的阈值通常是5%或1%。为什么是这些数字?仅仅因为它们是漂亮的整数。我们完全可以选择7%或0.389%,理论有效性不会改变。
- 它给人一种虚假的确定感。通过使用阈值,我们给出一个是/否的答案:显著或不显著。这可能给人一种答案是确定的错觉。不幸的是,科学中没有确定性这回事。所有结果都在一个连续体中,没有有意义的阈值。
- 它没有考虑风险规避。风险规避的概念在决策中是基础的。我们知道人类(和公司)尽可能地倾向于避免风险。P值和置信区间完全没有考虑到这一点。
那么呢?仅仅因为"统计显著性"不起作用,我们就应该避免做决策吗?
当然不是。我们应该改变使用我们拥有的工具(例如自助法直方图)的方式。
5. 更好的决策方法
任何决策都伴随着风险和机会。基于数据的决策也不例外。所以,如果我们以上面的例子为例,风险和机会是什么?
假设我们每月有100万用户。这意味着我们预计我们的变更一年将带来约590万美元(这是每用户0.49美元 * 每月100万用户 * 12个月)。
相当不错,对吧?但这只是期望值,它没有告诉我们完整的情况。那么我们如何获得完整的画面呢?
我们可以通过将每个(从自助法获得的)10,000次虚拟实验的值乘以100万用户乘以12个月来计算其经济结果。
例如,如果根据一个模拟实验,测试组导致的每用户结果为-0.70美元,那么我们知道总体影响将为-840万美元(-0.70美元 * 100万 * 12)。
实际上,我们可以用这行代码计算10,000次虚拟实验中每一次的经济影响:
1 |
|
这是我们得到的直方图:
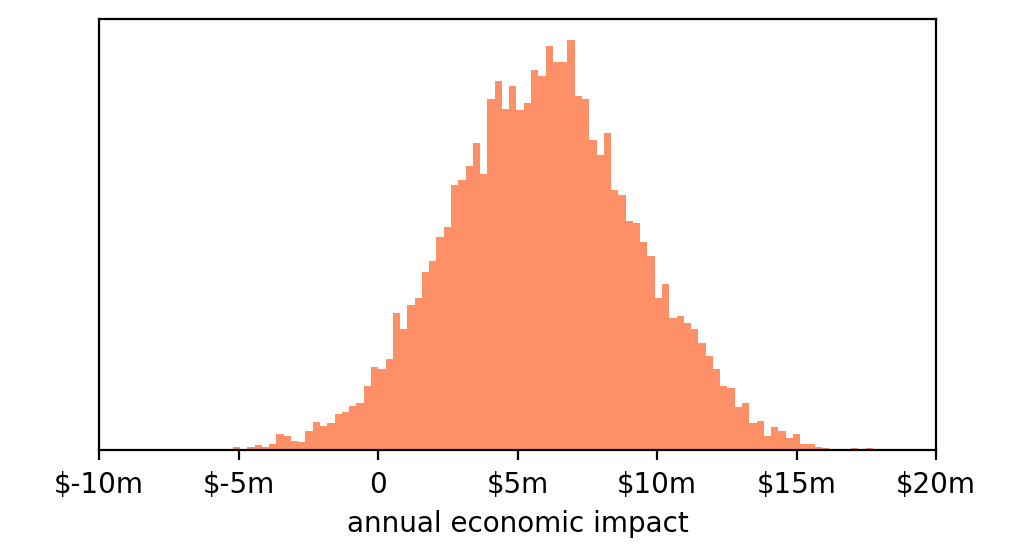
基本符合我们的预期:平均值约为+600万美元,但我们知道由于我们观察到的结果的变异性,结果可能相当极端,例如-400万美元或+1600万美元。
但我们已经知道,置信区间不会告诉我们太多信息。
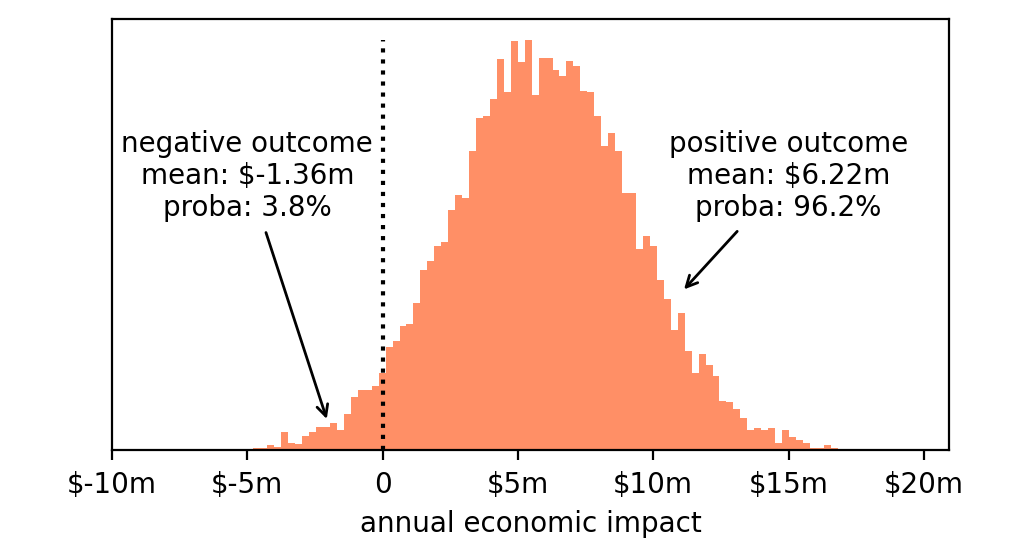
所以让我们回到对决策至关重要的基本概念:风险和机会。我们面临的风险和机会是什么?
- 风险:亏损。即使我们知道最可能的结果是+600万美元,实际结果也可能是经济损失(确实,直方图的一部分在零的左侧)。
- 机会:获利。毕竟,直方图的大部分在零的右侧,所以我们有合理的期望,这将导致一个积极的结果。
因此我们可以分析这两种可能性中的每一种,并测量它们的可能性以及实际发生时的预期结果。
- 亏损。如果我们推出这个变更,亏损的概率为3.8%,在这种情况下,我们将平均亏损136万美元。
- 获利。积极结果的概率为96.2%,在这种情况下,我们将平均获利622万美元。
那么,推出这个变更是个好主意吗?
答案取决于许多因素。考虑如下。这是我们愿意冒的风险吗?或者我们更愿意进行一个有更多用户参与的新测试来降低风险?如果是,我们有钱和时间运行另一个测试吗?是否有更有希望的变更我们想先测试?等等。
关键不在于我们决定什么。关键在于我们现在有更好的元素来做出决定。将这些权衡明确表达出来比隐藏在一个简单的问题后面要好得多:"它具有统计显著性吗? "