扫描PDF如何进行OCR+书签生成:不花一分钱,AI帮你完成
本文目录
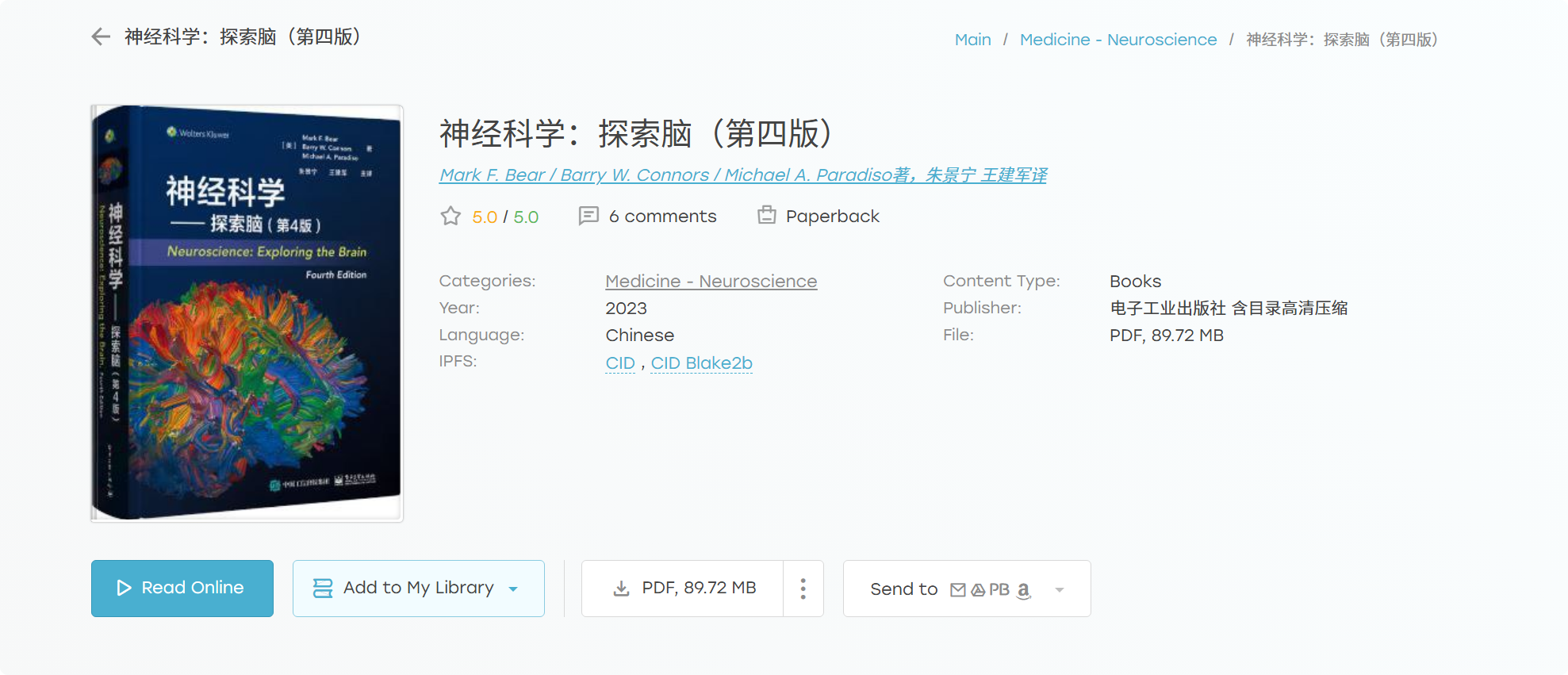
我在Zlibrary下载了《神经科学:探索脑》第四版的中文电子版
地址:神经科学:探索脑(第四版)
这本书是扫描版,没有OCR,无法选择文字;
虽然有书签目录,但是只到章节,我希望书签更详细一点
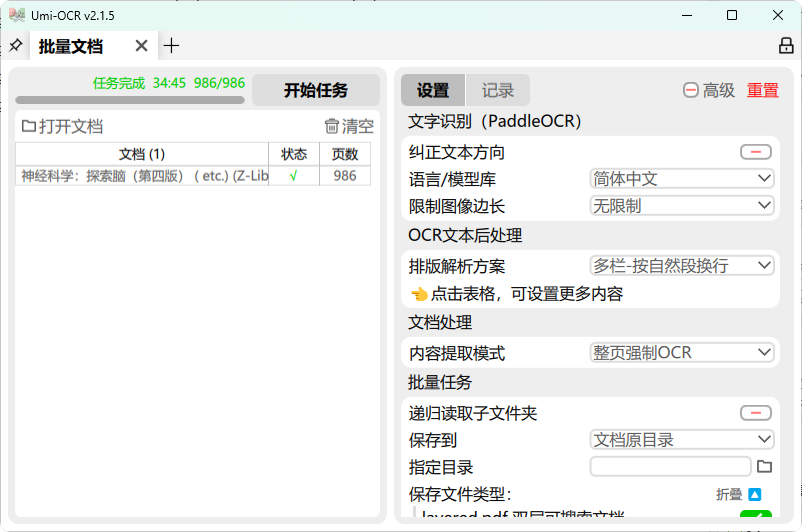
对扫描PDF进行快速OCR
推荐软件:github.com/hiroi-sora/Umi-OCR
开源免费,调用百度paddleOCR,中文OCR效果非常不错,并且OCR速度很快
内容提取模式 选择「整页强制OCR」
不用编程,使用PdgCntEditor一键生成PDF书签目录
发现有大佬开发了PdgCntEditor这个软件,可以以交互的方式快速生成pdf书签目录
下载地址:Windows PdgCntEditor PDF书签制作_3.15 便捷版
软件的交互逻辑
- 目录层级用制表符来区分(按Tab键)
- 书签标题与页码也是用制表符来区分,并支持自动切分页码
- 支持直接设置实际页码与目录页码的offset值
还是以《神经科学:探索脑》这本书为例子
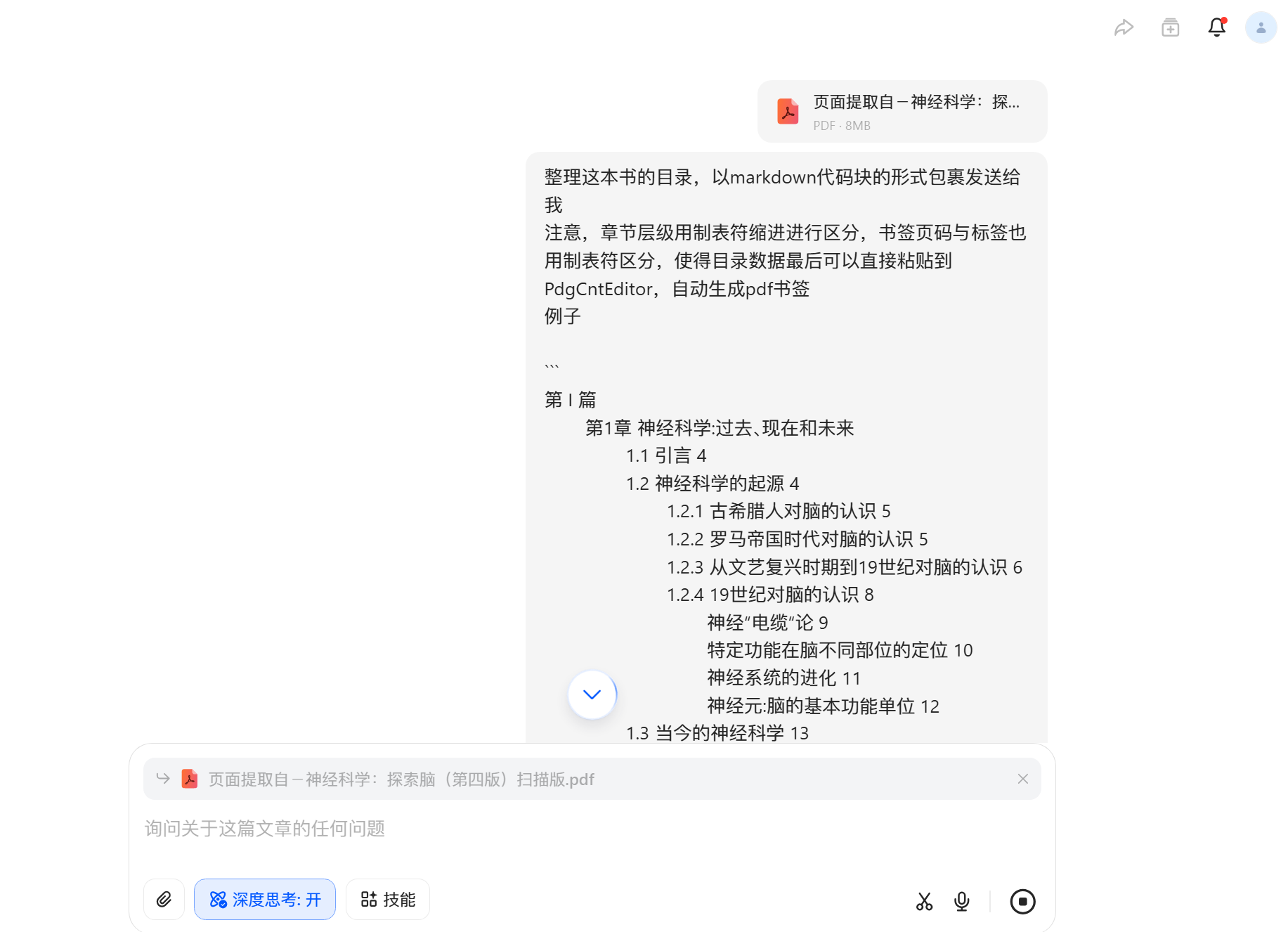
让AI自动生成目录数据
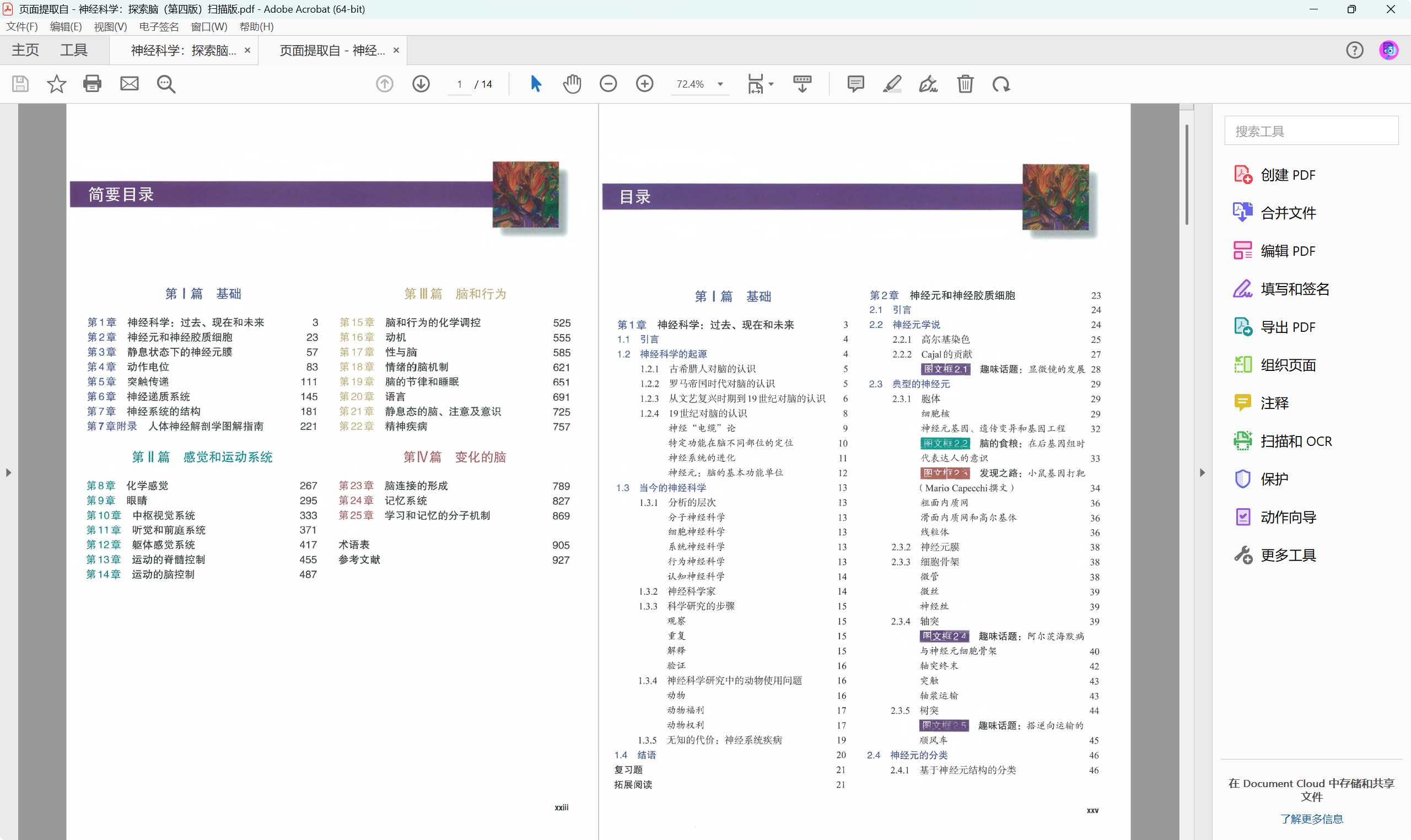
由于原书pdf太大了,先把目录页单独提取出来
发送给AI,让AI提取
GPT prompt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| 整理这本书的目录,以markdown代码块的形式包裹发送给我
注意,章节层级用制表符缩进进行区分,书签页码与标签也用制表符区分,使得目录数据最后可以直接粘贴到PdgCntEditor,自动生成pdf书签
例子
```
第 I 篇
第1章 神经科学:过去、现在和未来
1.1 引言 4
1.2 神经科学的起源 4
1.2.1 古希腊人对脑的认识 5
1.2.2 罗马帝国时代对脑的认识 5
1.2.3 从文艺复兴时期到19世纪对脑的认识 6
1.2.4 19世纪对脑的认识 8
神经“电缆“论 9
特定功能在脑不同部位的定位 10
神经系统的进化 11
神经元:脑的基本功能单位 12
1.3 当今的神经科学 13
1.3.1 分析的层次 13
```
|
目录识别效果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
| 第 I 篇 基础
第1 章 神经科学:过去、现在和未来 3
1.1 引言 4
1.2 神经科学的起源 4
1.2.1 古希腊人对脑的认识 5
1.2.2 罗马帝国时代对脑的认识 5
1.2.3 从文艺复兴时期到19世纪对脑的认识 6
1.2.4 19世纪对脑的认识 8
神经“电缆“论 9
特定功能在脑不同部位的定位 10
神经系统的进化 11
神经元:脑的基本功能单位 12
1.3 当今的神经科学 13
1.3.1 分析的层次 13
分子神经科学 13
细胞神经科学 13
系统神经科学 13
行为神经科学 13
认知神经科学 14
1.3.2 神经科学家 14
1.3.3 科学研究的步骤 15
观察 15
重复 15
解释 15
验证 16
1.3.4 神经科学研究中的动物使用问题 16
动物 16
动物福利 17
动物权利 17
1.3.5 无知的代价:神经系统疾病 19
1.4 结语 20
复习题 21
拓展阅读 21
第2 章 神经元和神经胶质细胞 23
2.1 引言 23
2.2 神经元学说 24
2.2.1 高尔基染色 25
2.2.2 Caj al 的贡献 27
趣味话题:显微镜的发展 28
2.3 典型的神经元 29
2.3.1 胞体 29
细胞核 29
神经元基因、遗传变异和基因工程 32
脑的食粮:在后基因组时代表达人的意识 33
发现之路:小鼠基因打靶(Mario Capecchi撰文) 34
粗面内质网 36
滑面内质网和高尔基体 36
线粒体 36
2.3.2 神经元膜 38
2.3.3 细胞骨架 38
微管 38
微丝 39
神经丝 39
2.3.4 轴突 39
趣味话题:阿尔茨海默病与神经元细胞骨架 40
轴突终末 42
突触 43
轴浆运输 43
2.3.5 树突 44
趣味话题:搭逆向运输的顺风车 45
2.4 神经元的分类 46
2.4.1 基于神经元结构的分类 46
神经突起数目 46
树突 46
趣味话题:智力障碍与树突棘 47
连接 48
轴突长度 48
2.4.2 基于基因表达的分类 48
2.5 神经胶质细胞 49
2.5.1 星形胶质细胞 49
2.5.2 成髓鞘胶质细胞 49
脑的食粮:用不可思议的Cre了解神经元的结构和功能 50
2.5.3 其他非神经元细胞 52
2.6 结语 53
关键词 53
复习题 54
拓展阅读 55
第3 章 静息状态下的神经元膜 57
3.1 引言 58
3.2 化学特性 59
3.2.1 细胞质和细胞外液 59
水 60
离子 60
3.2.2 磷脂膜 61
3.2.3 蛋白质 61
蛋白质的结构 61
通道蛋白 64
离子泵 65
3.3 离子的运动 66
3.3.1 扩散 66
3.3.2 电学 66
脑的食粮:摩尔和摩尔浓度 67
3.4 静息膜电位产生的离子基础 68
3.4.1 平衡电位 69
脑的食粮:能斯特方程 72
3.4.2 离子的跨膜分布 72
3.4.3 膜在静息状态下对离子的相对通透性 74
五彩续纷的钾通道 74
脑的食粮:戈德曼方程 75
调节细胞外钾浓度的重要性 76
发现之路:在黑暗中探索离子通道(Chri s Miller 撰文) 78
趣味话题:致死注射 80
3.5 结语 80
关键词 80
复习题 81
拓展阅读 81
第4 章 动作电位 83
4.1 引言 84
4.2 动作电位的特性 84
4.2.1 单个动作电位的上升相和下降相 84
4.2.2 单个动作电位的产生 84
脑的食粮:记录动作电位的方法 85
4.2.3 多个动作电位的产生 86
光遗传学:用光控制神经元的电活动 88
发现之路:通道型视紫红质类物质的发现(Georg Nagel 撰文) 88
4.3 理论上的动作电位 90
4.3.1 膜电流和膜电导 90
4.3.2 动作电位过程中离子的进出 92
4.4 实际的动作电位 92
4.4.1 电压门控钠通道 94
钠通道的结构 94
钠通道的功能特性 96
脑的食粮:膜片钳方法 97
毒素对钠通道的影响 98
4.4.2 电压门控钾通道 99
4.4.3 小结 100
4.5 动作电位的传导 102
4.5.1 影响传导速度的因素 103
趣味话题:局部麻醉 104
4.5.2 髓鞘和跳跃式传导 105
趣味话题:多发性硬化一种脱髓鞘疾病 105
4.6 动作电位、轴突和树突 106
4.7 结语 107
趣味话题:神经元多样的电活动 108
关键词 109
复习题 109
拓展阅读 110
第5 章 突触传递 111
5.1 引言 112
趣味话题: Otto Loewi 的梦 113
5.2 突触的类型 113
5.2.1 电突触 114
5.2.2 化学突触 115
中枢神经系统的化学突触 117
神经肌肉接头 119
发现之路:树突棘之爱(Kristen M. Harri s 撰文) 120
5.3 化学突触传递的原理 121
5.3.1 神经递质 122
5.3.2 神经递质的合成和存储 124
5.3.3 神经递质的释放 124
5.3.4 神经递质的受体和效应器 126
递质门控离子通道 126
脑的食粮:怎样捕捉囊泡 127
G 蛋白耦联受体 128
脑的食粮:逆转电位 129
自身受体 130
5.3.5 神经递质的重摄取和降韶 132
5.3.6 神经药理学 132
趣味话题:细菌、蜘蛛、蛇和人类 133
5.4 突触整合的原理 134
5.4.1 EPSP 的整合 134
EPSP 的量子分析 134
EPSP 的总和 135
5.4.2 树突性质对突触整合的贡献 135
树突的电缆性质 135
可兴奋的树突 137
5.4.3 抑制作用 138
IPSP 和分流抑制 138
趣味话题:惊吓反应突变体和毒物 139
兴奋性和抑制性突触的几何学 140
5.4.4 调制作用 140
5.5 结语 142
关键词 143
复习题 144
拓展阅读 144
第6 章 神经递质系统 145
6.1 引言 146
6.2 神经递质系统的研究 147
6.2.1 神经递质和递质合成酶的定位 147
免疫细胞化学 147
原位杂交 148
6.2.2 递质释放的研究 149
6.2.3 模拟突触的研究 150
6.2.4 受体的研究 150
神经药理学分析 151
配体结合法 153
发现之路:发现阿片受体(Solomon H. Snyder 撰文) 154
分子分析 155
6.3 神经递质的化学 155
6.3.1 胆碱能神经元 156
脑的食粮:泵入离子和递质 156
6.3.2 儿茶酚胺能神经元 158
6.3.3 5-轻色胺能神经元 160
6.3.4 氨基酸能神经元 161
6.3.5 其他的神经递质候选物和细胞间的信使物质 161
趣味话题:这就是你"嗜好“内源性大麻素的脑 162
6.4 递质门控通道 165
6.4.1 递质门控通道的基本结构 165
6.4.2 氨基酸门控通道 166
谷氨酸门控通道 167
趣味话题:兴奋性毒物:好东西太多也坏事 169
GABA 门控和甘氨酸门控通道 170
6.5 G 蛋白耦联受体和效应器 171
6.5.1 G 蛋白耦联受体的基本结构 171
6.5.2 广泛分布的G 蛋臼 172
6.5.3 G 蛋臼耦联效应器系统 173
快捷通路 173
第二信使级联反应 174
磷酸化和去磷酸化 176
信号级联反应的功能 176
6.6 神经递质系统的辐散和会聚 178
6.7 结语 179
关键词 179
复习题 180
拓展阅读 180
第7 章 神经系统的结构 181
7.1 引言 182
7.2 哺乳动物神经系统的大体组构 182
7.2.1 解剖学参照面 182
7.2.2 中枢神经系统 185
大脑 185
小脑 185
脑干 185
脊髓 185
7.2.3 外周神经系统 186
外周躯体神经系统 186
外周内脏神经系统 187
传入和传出轴突 187
7.2.4 脑神经 187
7.2.5 脑脊膜 187
7.2.6 脑室系统 188
7.2.7 新的脑成像方法 188
趣味话题:脑积水 189
活体脑结构成像 190
功能性脑成像 190
脑的食粮:磁共振成像 191
脑的食粮: PET 和fMRI 192
7.3 通过发育了解中枢神经系统的结构 194
7.3.1 神经管的形成 195
趣味话题:营养与神经管196
7.3.2 3 个初级脑泡 197
7.3.3 前脑的分化 198
端脑和间脑的分化 198
前脑的结构-功能关系 200
7.3.4 中脑的分化 201
中脑的结构-功能关系 202
7.3.5 后脑的分化 202
后脑的结构-功能关系 204
7.3.6 脊髓的分化 205
脊髓的结构-功能关系 205
7.3.7 小结206
7.3.8 人类中枢神经系统的特征 207
7.4 大脑皮层导览 210
7.4.1 大脑皮层的类型 210
7.4.2 新皮层的分区 212
新皮层的进化和结构-功能关系 212
发现之路:连接神经元的“连接组”(Sebastian Seung撰文) 214
7.5 结语 216
关键词 218
复习题 219
拓展阅读 219
第7 章附录 人体神经解剖学图解指南 221
第 II 篇 感觉和运动系统
第8 章 化学感觉 267
8.1 引言 268
8.2 味觉 268
8.2.1 基本味觉 269
8.2.2 味觉器官 269
趣味话题:奇怪的味道:脂肪味、淀粉味、碳酸味、钙味、水味? 270
8.2.3 味觉感受器细胞 271
8.2.4 味觉转导的机制 273
咸味 273
酸味 274
苦味 275
甜味 275
鲜味(氨基酸) 276
8.2.5 中枢味觉通路 276
趣味话题:对一次非常槽糕的饮食的记忆 278
8.2.6 味觉的神经编码 279
8.3 嗅觉 280
8.3.1 嗅觉器官 280
趣味话题:人类的外激素? 281
8.3.2 嗅觉感受器神经元 282
嗅觉的转导 282
嗅觉受体蛋白 284
cAMP 门控通道 285
发现之路:视觉和嗅觉的通道(Geoffrey Gold 撰文) 286
8.3.3 中枢嗅觉通路 287
8.3.4 嗅觉信息的时间和空间表征 289
嗅觉的群体编码 289
嗅觉定位图 290
嗅觉系统的时间编码 292
8.4 结语 293
关键词 293
复习题 294
拓展阅读 294
第9 章 眼睛 295
9.1 引言 296
9.2 光的特性 297
9.2.1 光 297
9.2.2 光学 297
9.3 眼睛的结构 298
9.3.1 眼睛的大体解剖 298
9.3.2 眼睛的检眼镜下观 299
趣味话题:展示你眼睛的盲区 300
9.3.3 眼睛的横切面解剖 300
9.4 眼睛中图像的形成 301
9.4.1 角膜的折射 301
趣味话题:眼睛的疾患 302
9.4.2 晶状体的适应性调节 303
趣味话题:视力矫正 304
9.4.3 瞳孔对光反射 305
9.4.4 视野 306
9.4.5 视锐度 306
9.5 视网膜的显微解剖 306
9.5.1 视网膜的分层组构 307
9.5.2 光感受器的结构 308
发现之路:通过相互镶嵌的光感受器看东西(Dav id Williams 撰文) 310
9.5.3 视网膜结构的区域差异及其对视觉的影响 312
9.6 光转导 314
9.6.1 视杆细胞的光转导 314
9.6.2 视锥细胞的光转导 317
颜色感知 318
趣味话题:色觉的遗传学318
9.6.3 暗适应和明适应 320
钙在明适应过程中的作用 320
对明暗和颜色的局部适应 320
9.7 视网膜的信息处理和输出 321
9.7.1 感受野 322
9.7.2 双极细胞的感受野 323
9.7.3 视神经节细胞的感受野 325
结构与功能之间的关系 327
颜色对立型视神经节细胞 327
9.7.4 视神经节细胞光感受器 329
9.7.5 并行处理 330
9.8 结语 330
关键词 331
复习题 332
拓展阅读 332
第10 章 中枢视觉系统 333
10.1 引言 334
10.2 离视网膜投射 335
10.2.1 视神经、视交叉和视束 335
10.2.2 左右半视野 336
10.2.3 视束的靶区 337
丘脑外区域的视束靶区 337
趣味话题:大卫和歌利亚 339
10.3 外侧膝状体核 340
10.3.1 眼睛和不同类型视神经节细胞输入的分离 341
10.3.2 感受野 342
10.3.3 外侧膝状体核中的非视网膜输入 343
10.4 纹状皮层的解剖 343
10.4.1 视拓扑 344
10.4.2 纹状皮层的分层 345
各亚层中的细胞 346
10.4.3 纹状皮层的输入和输出 346
自第IVC 层至其他皮层亚层的神经支配 347
眼优势柱 347
纹状皮层的输出 349
10.4.4 细胞色素氧化酶斑块 349
10.5 纹状皮层的生理 349
10.5.1 感受野 350
双眼视觉 350
方位选择性 350
脑的食粮:由光学成像和钙成像所揭示的皮层组构 352
方向选择性 352
简单感受野和复杂感受野 353
斑块感受野355
10.5.2 平行通路和皮层模块356
平行通路356
皮层模块357
10.6 纹区外视皮层358
10.6.1 背侧通路360
MT 区360
背侧区域和运动处理360
10.6.2 腹侧通路361
V4 区361
IT 区361
发现之路:在脑中寻找面孔(Nancy Kanw isher 撰文) 362
10.7 从单个神经元到感知 364
10.7.1 感受野的等级和感知 365
趣味话题:神奇的3D视觉 366
10.7.2 并行处理和感知 367
10.8 结语 368
关键词 368
复习题369
拓展阅读369
第11 章 听觉和前庭系统 371
11.1 引言372
11.2 声音的自然属性372
趣味话题:超声和次声374
11.3 听觉系统的结构375
11.4 中耳376
11.4.1 中耳的组成部分376
11.4.2 听小骨对声压的放大作用376
11.4.3 减弱反射378
11.5 内耳379
11.5.1 耳蜗的解剖379
11.5.2 耳蜗的生理380
基底膜对声音的反应 381
科蒂器及其相关结构 382
趣味话题:耳聋者也可以听到声音:人工耳蜗的植入 384
毛细胞的信号转导 384
毛细胞和听神经轴突 388
外毛细胞的放大作用 388
趣味话题:用充满噪声的耳朵听 389
11.6 中枢的听觉处理 390
11.6.1 听觉通路的解剖 391
11.6.2 听觉通路神经元的反应特征 391
11.7 声音强度和频率的编码 393
11.7.1 刺激强度 393
11.7.2 刺激频率、音调拓扑和锁相 393
音调拓扑 393
锁相 394
11.8 声音定位的机制 395
发现之路:捕捉声音的节拍(Donata Oertel 撰文) 396
11.8.1 水平平面中声音的定位 396
双耳神经元对声音位置的敏感性 398
11.8.2 垂直平面中声音的定位 400
11.9 听皮层 401
11.9.1 神经元的反应特征 402
趣味话题:听皮层是怎样工作的?-向”专才“求教 402
11.9.2 听皮层损伤和切除的效应 404
趣味话题:听觉功能紊乱及其治疗 404
11.10 前庭系统 405
11.10.1 前庭迷路 405
11.10.2 耳石器官 406
11.10.3 半规管 408
11.10.4中枢前庭通路和前庭反射 410
前庭-眼反射 411
11.10.5 前庭的病理学 412
11.11 结语 413
关键词 414
复习题 415
拓展阅读 415
第12 章 躯体感觉系统 417
12.1 引言 418
12.2 触觉 418
12.2.1 皮肤的机械感受器 419
振动觉和环层小体 421
机械敏感性离子通道 422
两点辨别觉 422
12.2.2 初级传入轴突 424
12.2.3 脊髓 425
脊髓的节段性组构 425
脊髓的感觉组构 428
12.2.4 背柱-内侧丘系通路 428
趣味话题:疤疹、带状疱疹和皮节 428
12.2.5 三叉神经触觉通路 430
脑的食粮:侧向抑制 431
12.2.6 躯体感觉皮层 432
皮层的躯体感觉定位 433
发现之路:皮层桶(Thomas Woolsey撰文) 436
皮层躯体感觉定位图的可塑性 437
后顶叶皮层 438
12.3 痛觉 439
趣味话题:没有疼痛的痛苦生活 440
12.3.1 伤害性感受器和痛刺激的转导 440
伤害性感受器的类型 441
痛觉过敏和炎症 441
趣味话题:热辣和辛辣 442
12.3.2 痒觉 443
12.3.3 初级传入纤维和脊髓机制 444
12.3.4 痛觉的上行通路 445
脊髓丘脑的痛觉通路 446
三又神经的痛觉通路 447
丘脑和大脑皮层 447
12.3.5 痛觉的调节 448
传入调节 448
下行调节 448
内源性阿片类物质 450
趣味话题:疼痛和安慰剂效应 450
12.4 温度觉 451
12.4.1 温度感受器 451
12.4.2 温度觉通路 453
12.5 结语 453
关键词 453
复习题 454
拓展阅读 454
第13 章 运动的脊髓控制 455
13.1 引言 456
13.2 躯体运动系统 456
13.3 下运动神经元 458
13.3.1 下运动神经元的节段性组构 459
13.3.2 a运动神经元 460
a 运动神经元对肌肉收缩的等级性控制 461
a 运动神经元的输入 461
13.3.3 运动单位的类型 463
神经肌肉的匹配 463
趣味话题:肌萎缩侧索硬化:谷氨酸、基因和Gehrig 465
13.4 兴奋-收缩耦联 466
13.4.1 肌纤维的结构 466
趣味话题:重症肌无力 466
13.4.2 肌肉收缩的分子基础 468
趣味话题:迪谢内肌营养不良 470
13.5 运动单位的脊髓控制 471
13.5.1 来自肌梭的本体感觉 471
牵张反射 472
发现之路:神经再生并不能保证完全康复(Timothy C. Cope 撰文) 474
13.5.2 'Y运动神经元 474
13.5.3 来自高尔基腿器官的本体感觉 477
来自关节的本体感觉 478
13.5.4 脊髓中间神经元 478
抑制性输入 479
兴奋性输入 479
13.5.5 行走的脊髓运动程序的发生 480
13.6 结语 483
关键词 484
复习题 484
拓展阅读 485
第14 章 运动的脑控制 487
14.1 引言 488
14.2 下行脊髓束 489
14.2.1 外侧通路 490
外侧通路损毁的效应491
14.2.2腹内侧通路492
趣味话题:麻痹、瘫痪、痉挛和巴宾斯基征492
前庭脊髓束493
顶盖脊髓束493
脑桥网状脊髓束和延髓网状脊髓束 494
14.3 大脑皮层对运动的计划 495
14.3.1 运动皮层 496
14.3.2 后顶叶皮层和前额叶皮层的贡献 497
14.3.3 运动计划相关神经元 498
趣味话题:行为神经生理学 499
14.3.4 镜像神经元 499
14.4 基底神经节 502
14.4.1 基底神经节的解剖 502
14.4.2 经基底神经节的直接通路和间接通路502
基底神经节疾病 505
趣味话题:病变基底神经节中的神经元会自杀吗? 506
趣味话题:损毁和刺激:治疗脑疾病的有效疗法 508
14.5 初级运动皮层对运动的发起 509
14.5.1 Ml 的输入-输出组构 510
14.5.2 Ml 的运动编码 511
可塑的运动图 513
发现之路:上丘的分布式编码(James T. Mcllwain 撰文) 514
14.6 小脑 514
趣味话题:正常的和异常的非随意运动 516
14.6.1 小脑的解剖 517
14.6.2 经小脑外侧部的运动环路 518
小脑的编程519
14.7 结语520
关键词521
复习题521
拓展阅读522
第 Ill 篇 脑和行为
第15 章 脑和行为的化学调控525
15.1 引言526
15.2 具有分泌功能的下丘脑528
15.2.1 下丘脑概述528
稳态528
下丘脑的结构和联系528
15.2.2 到垂体的通路529
下丘脑对垂体后叶的控制 529
下丘脑对垂体前叶的控制 532
趣味话题:应激和脑535
15.3 自主神经系统 535
15.3.1 自主神经系统环路 536
交感神经部和副交感神经部 537
肠神经部 539
自主神经系统的中枢控制 541
15.3.2 自主性功能的神经递质和药理学 541
节前神经递质 541
节后神经递质 542
15.4 脑的弥散性调制系统 542
15.4.1 弥散性调制系统的解剖和功能 543
去甲肾上腺素能的蓝斑核 543
趣味话题:想吃什么,也许你就缺什么 544
5-经色胺能的中缝核 545
探索中枢去甲肾上腺素能神经元(Floyd Bloom 撰文) 546
多巴胺能的黑质和腹侧被盖区 546
胆碱能的基底前脑复合体和脑干复合体 549
15.4.2 药物和弥散性调制系统 550
致幻剂 550
兴奋剂 550
15.5 结语 552
关键词 552
复习题 553
拓展阅读 553
第16 章 动机 555
16.1 引言 556
16.2 下丘脑、自稳态和动机性行为 556
16.3 摄食行为的长时程调节 557
16.3.1 能量平衡 557
16.3.2 体脂和摄食的体液调节和下丘脑调节558
体脂和食物的消耗 558
趣味话题:肥胖者饥饿的脑 560
下丘脑和摄食 560
瘦素水平升高对下丘脑的影响 561
瘦素水平降低对下丘脑的影响 562
下丘脑外侧区肤类物质对摄食的控制 564
16.4 摄食行为的短时程调节 565
16.4.1 食欲、进食、消化和饱 566
趣味话题:大麻和饥饿感567
促生长激素释放素568
胃扩张568
缩胆裳素568
胰岛素 568
趣味话题:糖尿病和胰岛素休克 569
16.5 我们为什么要吃饭? 570
16.5.1 强化和奖励 570
趣味话题:人脑的自我刺激 571
16.5.2 多巴胺在动机形成中的作用 572
趣味话题:多巴胺和成瘾 573
16.5.3 5-轻色胺、食物和情绪 575
16.6 其他动机性行为 575
发现之路:了解渴求(Julie Kauer 撰文) 576
16.6.1 饮水 576
16.6.2 体温调节 578
16.7 结语 580
趣味话题:神经经济学 581
关键词 582
复习题 582
拓展阅读 583
第17 章 性与脑585
17.1 引言586
17.2 生物学的性别和行为学的性别586
17.2.1 性别的遗传587
性染色体异常588
17.2.2 性别的发育和分化589
17.3 性别的激素控制590
17.3.1 主要的雄性和雌性激素 590
17.3.2 垂体和下丘脑对性激素的控制 591
17.4 性行为的神经基础 593
17.4.1 生殖器官及它们的控制 593
17.4.2 哺乳动物的交配策略 594
17.4.3 生殖行为的神经化学 596
发现之路:走近田鼠(Thomas Insel 撰文) 598
17.4.4 爱、亲密关系的建立与人脑 600
17.5 雄性和雌性的脑为何及如何不同 601
17.5.1 中枢神经系统的性别二态性 602
17.5.2 认知的性别二态性 604
17.5.3 性激素、脑和行为 605
胚胎脑的雄性化 605
趣味话题:鸟呜与脑 607
遗传的性别与激素作用之间的错配 608
17.5.4 遗传对行为和脑性别分化的直接作用 609
趣味话题: Dav id Reimer和性别认同的基础 610
17.5.5 性激素的激活作用 612
与母性和父性行为相关的脑变化 612
雌激素对神经元功能、记忆和疾病的影响 614
17.5.6 性取向 616
17.6 结语 618
关键词 618
复习题619
拓展阅读619
第18 章 情绪的脑机制621
18.1 引言622
18.2 早期的情绪学说622
18.2.1 詹姆斯-朗厄学说623
18.2.2 坎农-巴德学说623
18.2.3 无意识情绪的含义625
趣味话题:忐忑不安 626
18.3 边缘系统 627
18.3.1 Broca 边缘叶 628
18.3.2 Papez 环 628
趣味话题: PhineasGage 630
18.3.3 单一情绪系统概念的困境 630
18.4 情绪学说和神经表征 631
18.4.1 基本情绪学说 632
18.4.2 维度情绪学说 632
发现之路:日常科学中的概念和名称(Anton io Damasio 撰文) 634
18.4.3 情绪是什么 635
18.5 恐惧和杏仁核 636
18.5.1 克吕弗-布西综合征 636
18.5.2 杏仁核的解剖 637
18.5.3 刺激和损毁杏仁核的效应 638
18.5.4 习得性恐惧的神经回路 639
18.6 愤怒和攻击 641
18.6.1 杏仁核和攻击 641
减少人类攻击性的外科手术 642
18.6.2 杏仁核之外的愤怒和攻击的神经结构 642
趣味话题:额叶切断术 643
愤怒、攻击和下丘脑 644
中脑和攻击 645
18.6.3 愤怒和攻击的5-胫色胺能神经调节 646
18.7 结语 647
关键词 648
复习题 649
拓展阅读 649
第19 章 脑的节律和睡眠 651
19.1 引言 652
19.2 脑电图 652
19.2.1 脑电波的记录 653
发现之路:脑节律之谜(S tephan i e R. Jones 撰文) 656
19.2.2 EEG 节律 656
19.2.3 脑节律的机制和意义 659
同步化节律的产生 659
脑节律的功能意义 661
19.2.4 癫病发作 661
19.3 睡眠 664
19.3.1 脑的功能状态 664
19.3.2 睡眠循环 666
趣味话题:睡眠时的行走、讲话和尖叫 667
19.3.3 我们为什么要睡眠? 668
趣味话题:最长的不眠之夜 670
19.3.4 梦和REM 睡眠的功能 670
19.3.5 睡眠的神经机制 672
觉醒与上行性网状激活系统 672
趣味话题:发作性睡病 674
入睡和非REM 睡眠状态 675
REM 睡眠的机制 676
促睡眠因子 677
睡眠和觉醒状态下的基因表达 679
19.4 昼夜节律 679
19.4.1 生物钟 680
19.4.2 视交叉上核:一种脑时钟 682
趣味话题:突变仓鼠的生物钟 684
19.4.3 视交叉上核的机制 685
19.5 结语 687
关键词 688
复习题 688
拓展阅读 689
第20 章 语言 691
20.1 引言 692
20.2 什么是语言? 692
20.2.1 人类的发音和言语的产生 692
20.2.2 动物的语言 693
趣味话题:用不同的语言思考 694
20.2.3 语言的习得 696
20.2.4 与语言相关的基因 698
FOXP2 和言语运用障碍 698
特定型语言障碍和阅读障碍的遗传因素 699
20.3 脑内特异性语言区的发现 700
20.3.1 Broca 区和Wem icke 区 701
趣味话题:评估语言优势半球 702
20.4 通过对失语症的研究深入了解语言 703
20.4.1 Broca 失语症 703
揭示脑的语言区域(Nina Dronkers 撰文) 704
20.4.2 Wemicke 失语症 706
20.4.3 语言的Wernicke-Geschw ind 模型和失语症 708
20.4.4 传导性失语症 711
20.4.5 双语者和耳聋者的失语症 711
20.5 大脑两半球语言加工的不对称性 712
20.5.1 裂脑人的语言加工 713
左半球的语言优势 714
右半球的语言功能 714
20.5.2 解剖的不对称性和语言 715
20.6 利用脑刺激和人脑成像研究语言 717
20.6.1 脑刺激对语言的影响 717
20.6.2 人脑语言加工的脑成像 719
趣味话题:用眼听和用手看 720
20.7 结语 722
关键词 723
复习题 724
拓展阅读 724
第21 章 静息态的脑、注意及意识 725
21.1 引言 726
21.2 静息态的脑活动 726
21.2.1 脑的默认模式网络 726
默认网络的功能 728
21.3 注意 729
趣味话题:注意缺陷多动症 730
21.3.1 注意对行为的影响 731
注意可以提高视觉敏感性 731
注意可以加快反应速度 733
21.3.2 注意的生理效应 734
人类空间注意的fMRI 成像研究 734
人类特征注意的PET 成像研究 735
注意增强顶叶皮层中神经元的反应 737
注意聚焦于V4 感受野 739
21.3.3 调控注意的脑环路 740
丘脑枕,一个皮层下结构 740
额叶眼区、眼球运动和注意 741
利用显著特征和优先级引导注意 742
顶叶的优先级图 742
趣味话题:半侧忽视综合征 744
额顶叶注意网络 746
21.4 意识 748
21.4.1 什么是意识? 748
21.4.2 意识的神经关联 749
双眼竞争中交替感知的神经关联 749
发现之路:追寻意识神经元的足迹(Chri sto f Koch 撰文) 750
视觉意识和人脑的活动 751
意识研究领域里的挑战 753
21.5 结语 755
关键词 755
复习题 756
拓展阅读 756
第22 章 精神疾病 757
22.1 引言 758
22.2 精神疾病和脑 758
22.2.1 精神疾病的心理社会学探讨 759
22.2.2 精神疾病的生物学探讨 759
分子精神医学的前景和挑战 760
22.3 焦虑障碍 762
22.3.1 焦虑障碍概述 762
惊恐障碍 762
广场恐沛症 763
22.3.2 其他以焦虑增加为特征的障碍 763
创伤后应激障碍 763
强迫症 763
22.3.3 焦虑障碍的生物学基础 763
趣味话题:惊恐发作性广场恐怖症 764
应激反应 765
杏仁核和海马对HPA 轴的调节 766
22.3.4 焦虑障碍的冶疗 767
心理治疗 767
抗焦虑药物治疗 767
22.4 情感障碍 769
22.4.1 情感障碍概述 769
重性抑郁症 769
双相障碍 769
趣味话题:噩梦中神秘的橘黄色小树林 770
22.4.2 情感障碍的生物学基础 771
单胺假说 772
素质-应激假说 773
前扣带回皮层功能障碍 773
22.4.3 情感障碍的治疗 774
电休克治疗 774
心理治疗 774
抗抑郁剂 774
锂盐 776
深部脑刺激 777
22.5 精神分裂症 777
22.5.1 精神分裂症概述 777
发现之路:调控抑郁症的环路(Helen Mayberg撰文) 778
22.5.2 精神分裂症的生物学基础 780
基因和环境 780
多巴胺假说 781
谷氨酸假说 783
22.5.3 精神分裂症的冶疗 784
22.6 结语 785
关键词 785
复习题 786
拓展阅读 786
第IV篇 变化的脑
第23 章 脑连接的形成 789
23.1 引言 790
23.2 神经元的发生 791
23.2.1 细胞增殖 791
趣味话题:成年人的神经发生(或者说:神经科学家是怎么爱上核弹的) 792
23.2.2 细胞迁移 795
23.2.3 细胞分化 795
23.2.4 皮层区的分化 797
发现之路:绘制心灵的地图(Pasko Rakic 撰文) 798
23.3 神经元连接的发生 801
23.3.1 生长的轴突 802
23.3.2 轴突引导 803
引导信号 803
建立拓扑图 805
为什么我们中枢神经系统中的轴突不能再生? 806
23.3.3 突触的形成 807
23.4 细胞和突触的消除 808
趣味话题:自闭症之谜 809
23.4.1 细胞死亡 810
23.4.2 突触容最的改变 810
23.5 活动依赖性的突触重排 812
23.5.1 突触分离 812
LGN 中视网膜输入的分离 813
纹状皮层中LGN 输入的分离 814
三眼青蛙、眼优势柱和其他奇特现象 814
23.5.2 突触会聚 815
关键期的概念 816
23.5.3 突触竞争 817
23.5.4 调制性影响 818
23.6 皮层突触可塑性的基本机制 819
23.6.1 未成熟视觉系统中的兴奋性突触传递 820
23.6.2 长时程突触增强 821
23.6.3 长时程突触压抑 821
23.7 关键期为何会结束? 824
23.8 结语 825
关键词 825
复习题 826
拓展阅读 826
第24 章 记忆系统 827
24.1 引言 828
24.2 记忆和遗忘的类型 828
24.2.1 陈述性和非陈述性记忆 828
24.2.2 程序性记忆的类型 829
非联合型学习 829
趣味话题:超常记忆 830
联合型学习 831
24.2.3 陈述性记忆的类型 833
24.2.4 遗忘 833
24.3 工作记忆 835
24.3.1 前额叶皮层和工作记忆 835
人脑工作记忆的成像 837
24.3.2 LIP 区和工作记忆 837
24.4 陈述性记忆 839
24.4.1 新皮层和陈述性记忆 839
Hebb 和细胞集群 840
24.4.2 涉及内侧颐叶的研究 842
内侧颓叶的解剖结构 842
人脑颠叶的电刺激 843
人脑内侧颓叶的神经电活动记录 844
24.4.3 颐叶遗忘症 845
病例H.M.:颜叶切除术和遗忘症 845
人类遗忘症的一个动物模型 847
趣味话题:科尔萨科夫综合征和病例N.A. 849
24.4.4 海马系统的记忆功能 850
大鼠海马损伤后的效应 850
空间记忆、位置细胞和网格细胞 851
发现之路:脑是怎样绘制地图的(Edvard Moser 和May-Britt Moser 撰文) 854
除空间记忆之外的海马功能 856
24.4.5 记忆的巩固和记忆痕迹的保留 857
记忆巩固的标准模型和多重痕迹模型 858
记忆的再巩固 860
24.5 程序性记忆 861
24.5.1 啮齿动物的纹状体和程序性记忆 861
趣味话题:虚假记忆的引入和负性记忆的抹除 862
24.5.2 入类和非人灵长类的习惯学习 865
24.6 结语 866
关键词 867
复习题 868
拓展阅读 868
第25 章 学习和记忆的分子机制 869
25.1 引言 870
25.2 记忆的获得 871
25.2.1 记忆形成的细胞表现 871
记忆的分布式存储 873
发现之路:是什么引起了我对海兔学习和记忆的研究兴趣(Eric Kandel 撰文) 875
25.2.2 突触的强化 878
海马的解剖 878
CAI 区LTP 的特性 879
CAl 区LTP 的机制 881
脑的食粮:突触可塑性:时间就是一切 882
25.2.3 突触的弱化 883
发现之路:记忆的记忆(Leon Cooper 撰文) 884
脑的食粮:长时程突触压抑的大于世界 886
CAI 区LTD 的机制 888
谷氨酸受体的运输 888
25.2.4 LTP 、 LTD 与记忆 890
趣味话题:记忆突变体 892
25.2.5 突触的稳态 893
超可塑性 893
突触缩放 895
25.3 记忆的巩固 895
25.3.1 蛋臼激荫的持续激活 896
CaMK II 896
蛋白质激酶M ~ 897
25.3.2 蛋白质的合成与记忆的巩固 897
突触的标记与捕获 898
CREB 与记忆 898
结构可塑性与记忆 900
25.4 结语 901
关键词 902
复习题 902
拓展阅读 903
术语表 905
参考文献 927
|
PdgCntEditor创建pdf书签
- 自动切分页码
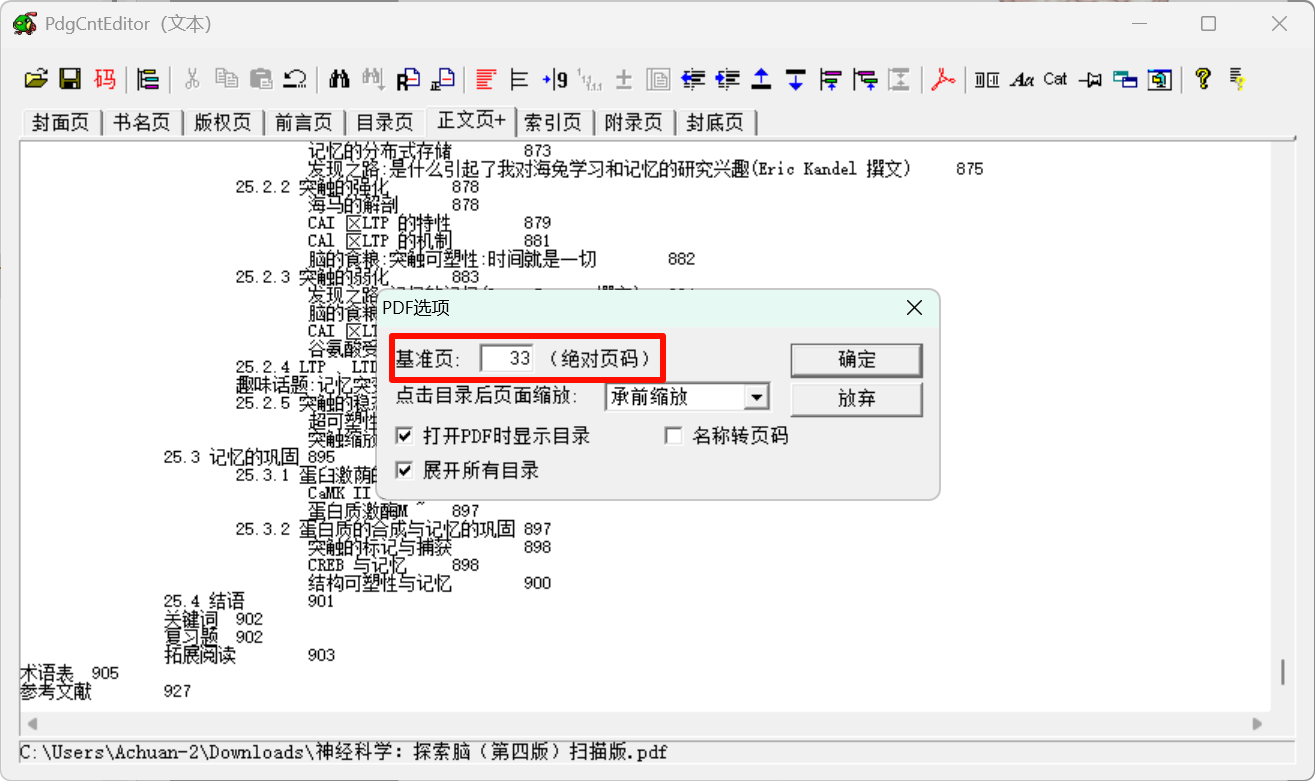
- 设置基准页:引言是第四页,但是在pdf实际上36页,说明基准页是36-4+1=33页
- 按Ctrl+S保存书签
效果展示
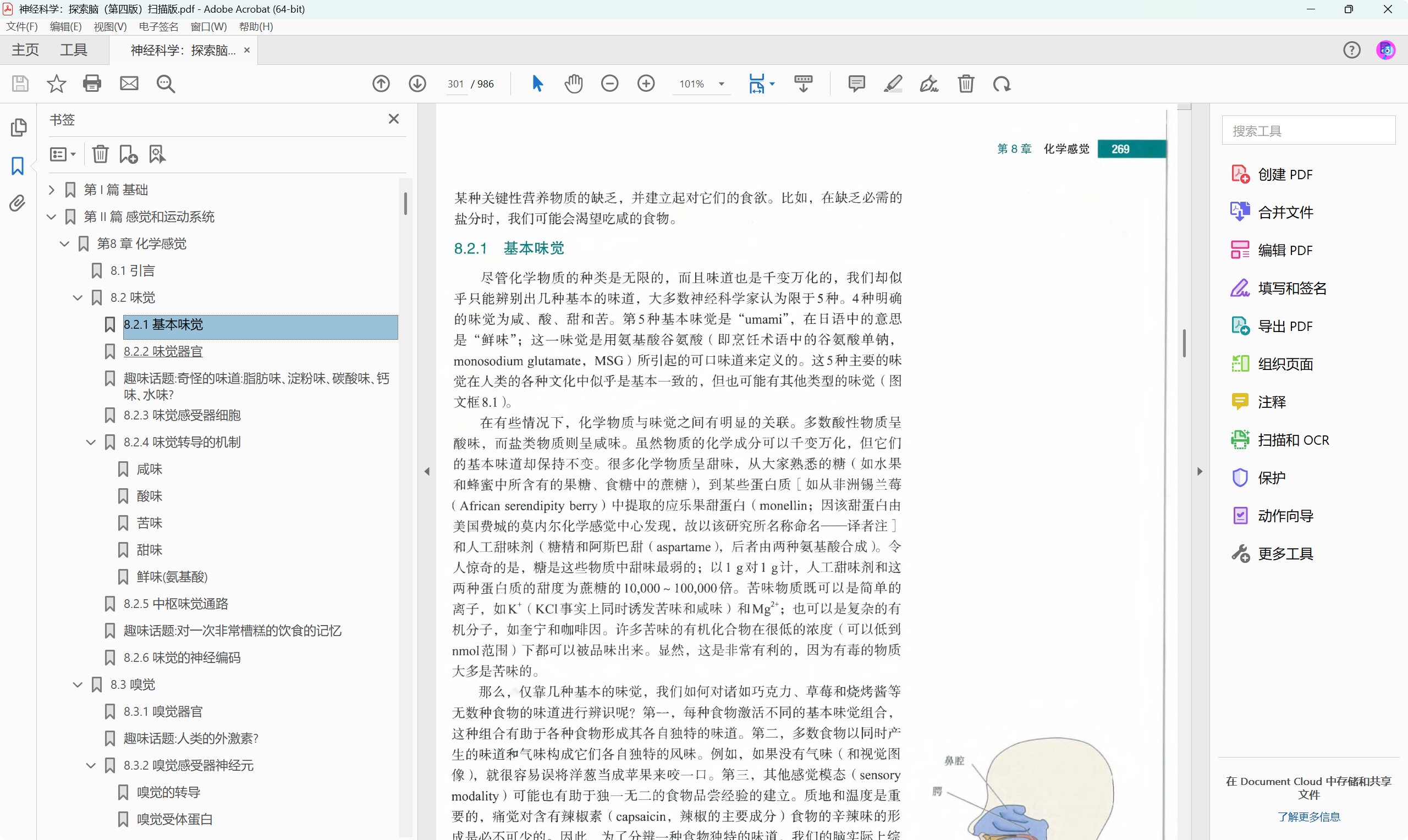
成功写入pdf书签,点击书签可以正确跳转
资源分享
公众号后台回复【神经科学探索脑】,自动获取《神经科学探索脑》英文版本、中文扫描版以及这篇文章处理得到的中文OCR+详细书签版本
公众号后台回复【PDF处理】,获取umi-OCR和PdgCntEditor软件链接
相关笔记
- 神经科学权威教科书:《神经科学原理(第六版)》中文翻译版本开源!