总结
-
Matlab使用
act1 = activations(net,im,'conv1');可以查看神经网络模型中指定图生成的activation图 -
激活图是什么
- 由卷积层生成的特征图 (Feature Map) 经过激活函数 (Activation Function) 处理后的结果。
- 激活图就像是CNN的"思维过程",展示了网络在识别图像时各个层次的关注点。简单说,它让我们窥探AI是如何"看"世界的!
-
激活图的意义
- 激活图上的每个值 (激活值) 代表了网络对该位置和对应特征的响应程度。 值越大,表示网络对该位置和特征越敏感,认为它越重要。
- 越深的层的激活图提取的特征越来越抽象:大多数卷积神经网络在第一个卷积层中学习检测颜色和边缘等特征。在更深的卷积层中,网络学习检测更复杂的特征。通过可视化激活图,我们可以观察不同卷积层学习到的特征,以及这些特征如何随着网络深度的增加而变得更加抽象和高级。
如何可视化卷积神经网络的激活
此示例说明如何将图像馈送到卷积神经网络并显示网络的不同层的激活。通过将激活区域与原始图像进行比较,检查激活并发现网络学习的特征。发现较浅层中的通道学习颜色和边缘等简单特征,而较深层中的通道学习眼睛等复杂特征。以这种方式识别特征可以帮助您了解网络学习的内容。
该示例需要 Deep Learning Toolbox™ 和 Image Processing Toolbox™。
加载预训练的网络和数据
加载一个预训练的 SqueezeNet 网络。
1 | net = squeezenet; |
读取并显示图像。保存图像大小,以便稍后使用。
1 | im = imread('face.jpg'); |

1 | imgSize = size(im); |
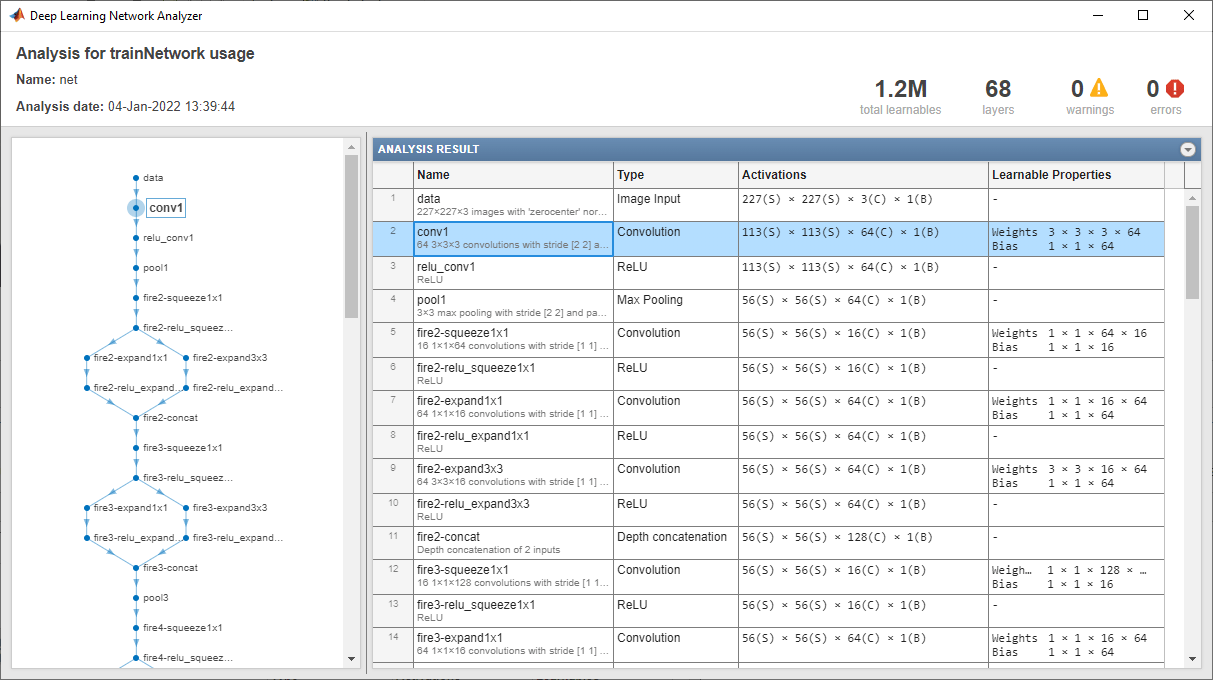
查看网络架构
分析该网络,了解您可以查看哪些层。卷积层使用可学习的参数执行卷积。网络学习识别有用的特征,通常每个通道对应一个特征。观察到第一个卷积层有 64 个通道。
1 | analyzeNetwork(net) |
图像输入层指定输入大小。您可以在将图像通过网络之前调整图像大小,但网络也可以处理较大的图像。如果您为网络提供较大的图像,则激活也会变大。但是,由于网络是基于大小为 227×227 的图像进行训练的,因此无法识别超过该大小的对象或特征。
显示第一个卷积层的激活
观察卷积层中的哪些区域在图像上激活,并将其与原始图像中的相应区域进行比较,以研究特征。卷积神经网络的每层由许多称为通道的二维数组组成。用图像对网络进行一轮训练,并检查 conv1 层的输出激活。
1 | act1 = activations(net,im,'conv1'); |
激活以三维数组的形式返回,其中第三个维度对 conv1 层上的通道进行索引。要使用 imtile 函数显示这些激活,请将数组重构为四维。imtile 的输入中的第三个维度表示图像颜色。将第三个维度的大小设置为 1,因为激活没有颜色。第四个维度对通道进行索引。
1 | sz = size(act1); |
现在您可以显示激活。每个激活都可能采用任何值,因此请使用 mat2gray 归一化输出。缩放所有激活值,以使最小激活值为 0,最大激活值为 1。在 8×8 网格上显示 64 个图像,层中的每个通道对应一个图像。
1 | I = imtile(mat2gray(act1),'GridSize',[8 8]); |

调查特定通道中的激活
激活网格中的每个图块都是 conv1 层中某个通道的输出。白色像素表示强的正激活,黑色像素表示强的负激活。主要为灰色的通道未对输入图像进行强烈激活。通道激活中的像素位置对应于原始图像中的相同位置。通道中某个位置的白色像素表示该通道在该位置强激活。
调整通道 22 中的激活大小以使其与原始图像具有相同的大小,并显示激活。
1 | act1ch22 = act1(:,:,:,22); |

您可以看到此通道在红色像素上激活,因为通道中的偏白的像素对应于原始图像中的红色区域。
查找最强的激活通道
您还可以通过编程方式调查具有大量激活值的通道来尝试查找感兴趣的通道。使用 max 函数查找具有最多激活值的通道,调整大小并显示这些激活值。
1 | [maxValue,maxValueIndex] = max(max(max(act1))); |

与原始图像进行比较,注意此通道在边缘激活。它在浅色左侧/深色右侧边缘上正激活,在深色左侧/浅色右侧边缘上负激活。
调查更深的层
大多数卷积神经网络在第一个卷积层中学习检测颜色和边缘等特征。在更深的卷积层中,网络学习检测更复杂的特征。较深的层通过组合较浅层的特征来构建其特征。以调查 conv1 层的方式调查 fire6-squeeze1x1 层。计算、重构并在网格中显示激活。
1 | act6 = activations(net,im,'fire6-squeeze1x1'); |

图像太多,无法详细调查,因此不妨关注一些更有趣的图像。显示 fire6-squeeze1x1 层中最强的激活。
1 | [maxValue6,maxValueIndex6] = max(max(max(act6))); |

在本例中,最大激活通道在详细特征方面不像其他一些通道那样令人感兴趣,并且表现出强力的负(深色)激活以及正(浅色)激活。此通道可能专注于面部。
在所有通道的网格中,可能有通道针对眼睛激活。进一步调查通道 14 和 47。
1 | I = imtile(imresize(mat2gray(act6(:,:,:,[14 47])),imgSize)); |

许多通道包含同时存在浅色和深色的激活区域。它们分别是正激活和负激活。但是,由于 fire6-squeeze1x1 层后面是修正线性单元 (ReLU),因此只使用正激活。要只调查正激活,请重复分析以可视化 fire6-relu_squeeze1x1 层的激活。
1 | act6relu = activations(net,im,'fire6-relu_squeeze1x1'); |

与 fire6-squeeze1x1 层的激活相比,fire6-relu_squeeze1x1 层的激活清楚地定位到具有强面部特征的图像区域。
测试通道是否识别眼睛
检查 fire6-relu_squeeze1x1 层的通道 14 和 47 是否针对眼睛激活。将两眼一睁一闭的新图像输入到网络中,并将得到的激活与原始图像的激活进行比较。
读取并显示两眼一睁一闭的图像,并计算 fire6-relu_squeeze1x1 层的激活。
1 | imClosed = imread('face-eye-closed.jpg'); |

1 | act6Closed = activations(net,imClosed,'fire6-relu_squeeze1x1'); |
在一个图窗中绘制图像和激活。
1 | channelsClosed = repmat(imresize(mat2gray(act6Closed(:,:,:,[14 47])),imgSize),[1 1 3]); |

您可以从激活中看到,通道 14 和 47 都针对单个眼睛激活,并且在某种程度上也针对嘴周围的区域激活。
网络从未被告知要学习眼睛的特征,但它已学习到眼睛是区分图像类的一个有用特征。以前的机器学习方法通常手动设计特定于问题的特征,但这些深度卷积网络可以为自己学习有用的特征。例如,学习识别眼睛可以帮助网络区分猎豹和豹纹地毯。
问题和笔记
-
The Image Input layer specifies the input size. You can resize the image before passing it through the network, but the network also can process larger images. If you feed the network larger images, the activations also become larger. However, since the network is trained on images of size 227-by-227, it is not trained to recognize objects or features larger than that size.
- 所以squeezenet是可以输入更大尺寸的图像的,只不过无法识别更大的物体?
- 在这个案例里没有对图像进行resize,说明是可以直接输入的
-
ReLU之后只有正activation,通过激活图来看就可以明显看出经过ReLU之后,特征会变得更加明显
- 与conv5层的激活相比,relu5层清晰地精确定位图像中具有强烈激活的面部区域特征。
- conv5层的激活图

- relu5层的激活图

-
正activation和负activation是什么?
- White pixels represent strong positive activations and black pixels represent strong negative activations.

资料
- Matlab官方文档(squeezenet):https://ww2.mathworks.cn/help/deeplearning/ug/visualize-activations-of-a-convolutional-neural-network.html
- MATLAB环境下可视化卷积神经网络CNN的激活图 - 知乎 (zhihu.com):用的是AlextNet来可视化激活图