主成分分析是一种常用的数据降维方法,它利用正交变换把由线性相关变量表示的观测数据转换为少数几个由线性无关变量表示的数据,这些线性无关的变量被称为主成分。
主成分分析计算指标权重用于对象综合评价的原理是能对信息进行压缩,把多个指标变换成几个综合指标,从而计算得到指标的权重和对象的综合得分。
为了计算指标的权重,将**PCA得到的特征向量当作指标在主成分中的“贡献系数**”,用来描述每个主成分对各个指标的依赖程度,将**各个主成分的累计方差贡献率**当作主成分的重要性权重,每个指标在不同主成分的特征向量值相乘主成分累计方差贡献率并加和即为对象的综合得分。
为了计算对象的综合得分,将PCA降维后的数据(主成分得分)当做是综合指标得分,将**各个主成分的累计方差贡献率**当作是主成分重要性权重,主成分得分相乘对应累计方差贡献率并加和即为对象的综合得分。
目录
-
主成分分析计算步骤
- 准备原始矩阵 X
- 计算正向化矩阵 X′
- KMO和Barlette检验
- 计算标准化矩阵 Z
- 计算协方差矩阵 R
- 计算特征值 和特征向量
- 计算主成分的方差贡献率和累计方差贡献率
- 根据一定的原则确定主成分数量 k
- 计算主成分系数/因子载荷
- 计算主成分得分
- 计算前 k
- 计算指标权重
- 计算对象综合得分
-
代码实现
- matlab实现
- python实现
-
相关考试题目
-
参考
主成分分析计算步骤
主成分分析计算权重以及综合评价的步骤如下:
1. 准备原始矩阵
假设有 个对象, 个指标,则原始数据矩阵为 的矩阵:
其中, 表示第 个对象在第 个指标下的评分数据。
例如
| 对象 | 指标1 | 指标2 | 指标3 |
|---|---|---|---|
| 对象1 | 1 | 3 | 1 |
| 对象2 | 2 | 2 | 2 |
| 对象3 | 2 | 1 | 3 |
| 对象4 | 3 | 2 | 1 |
2. 计算正向化矩阵
指标类型一般有三种:
- 正向指标,越大越好,如收入;
- 负向指标,越小越好,如成本;
- 适度指标,在某个范围最好,如水中的PH值,越接近7越好。
根据不同类型的指标,需要进行不同的正向化处理:
-
正向(极大型)指标: 无需变化
-
负向(极小型)指标:
-
适度指标:
其中 和 不相等时可以叫做范围型指标, 和 相等时可以叫做中间型指标。
3. KMO和Barlette检验
KMO检验:用于比较变量间的简单相关系数与偏相关系数
| KMO值 | 是否适合做主成分分析 |
|---|---|
| >0.8 | 非常适合 |
| 0.7~0.8 | 一般适合 |
| 0.6~0.7 | 不太适合 |
| 0.5~0.6 | 不适合 |
| <0.5 | 极不适合 |
Bartlett检验:检验相关系数矩阵是否是单位矩阵
-
假设
- 原假设 (H0): 相关系数矩阵为单位矩阵。
- 备择假设 (H1): 相关系数矩阵不是单位矩阵。
-
近似卡方值:用于衡量观测到的相关矩阵与单位矩阵之间的差异。
-
自由度 (df) :与卡方检验相关的自由度。
-
p值:如果p值小于0.05,则认为变量间存在足够的相关性,可以进行PCA。
4. 计算标准化矩阵
主成分分析最常用的标准化方法是 Z-score 标准化,即:
其中 和 分别是正向化矩阵 中第 个变量的均值和标准差。
将原数据变为均值为0,标准差为1的数据。
5. 计算协方差矩阵
标准化后的矩阵
对于已标准化的矩阵,我们可以使用以下公式计算其协方差矩阵:
其中:
- 表示第 个变量和第 个变量之间的相关系数。
- 表示样本数量。
- 表示第 个样本的第 个变量的标准化值。
- 表示第 个变量的标准化值的均值。
所以没有标准化的数据,是不能直接计算协方差矩阵的
未标准化的矩阵: 直接计算相关系数矩阵:
其中:
- 表示第 个变量和第 个变量之间的相关系数。
- 表示样本数量。
- 表示第 个样本的第 个变量的值。
- 表示第 个变量的均值。
相关系数也叫皮尔逊系数,分子是协方差,分母是标准差之积,相当于直接对原始矩阵计算的协方差进行了标准化。
6. 计算特征值 和特征向量
对于一个给定的 n 阶方阵 A,如果存在一个非零向量 和一个标量 λ,使得以下等式成立:
那么,λ 就被称为矩阵 A 的一个特征值,而 就被称为矩阵 A 对应于特征值 λ 的一个特征向量。
PCA会对协方差矩阵 进行特征分解,得到特征值
和对应的特征向量
7. 计算主成分的方差贡献率和累计方差贡献率
第 个主成分的方差贡献率定义为:
前 个主成分的累计方差贡献率定义为:
举例:
| 特征值 | 方差贡献率 | 累计方差贡献率 |
|---|---|---|
| 3 | 44% | 44% |
| 2 | 30% | 74% |
| 1 | 15% | 89% |
| 0.5 | 7% | 96% |
| 0.25 | 4% | 100% |
8. 根据一定的原则确定主成分数量
前 个主成分的累计方差贡献率 定义为:
确定主成分数量 的方法有以下几种,选择其中一种即可,不需要全部使用:
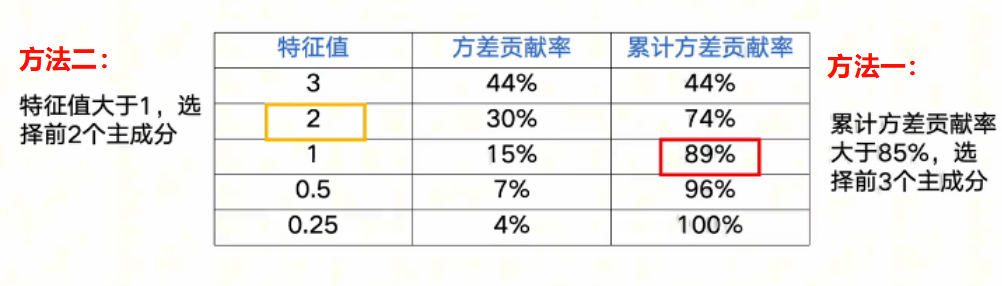
- 累计方差贡献率: 选择累计方差贡献率大于某个阈值(例如 85%)时的最小的 个主成分。阈值一般在 80%~90% 之间。
- 特征值: 选择特征值大于某个阈值(例如 1)时的最小的 个主成分。
- 手动选择: 根据业务经验确定主成分数量。
9. 计算主成分系数/因子载荷
主成分系数就为特征向量
载荷是特征向量乘以对应特征值的平方根,载荷代表每个主成分上各个原始变量的权重系数。
计算公式为:
10. 计算主成分得分
主成分得分即主成分分析对数据进行处理后,得到的数据在特征空间的投影。
在Python和Matlab中,可以直接通过调用函数得到,不需要手动计算。
手动计算的公式:主成分得分=标准化数据矩阵Z×特征向量矩阵A
如果我们选择了 个主成分,则只需要计算对象在这 个主成分上的得分即可。第 个对象在第 个主成分下的得分:
例子:
标准化矩阵Z:
| 对象 | 指标1 | 指标2 | 指标3 | 指标4 | 指标5 |
|---|---|---|---|---|---|
| A | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 |
| B | … | … | … | … | … |
| C | … | … | … | … | … |
| D | … | … | … | … | … |
| E | … | … | … | … | … |
| F | … | … | … | … | … |
| G | … | … | … | … | … |
前3个主成分的主成分系数(特征向量)矩阵A:
| 指标 | 主成分1 | 主成分2 | 主成分3 |
|---|---|---|---|
| 指标1 | 0.1 | … | … |
| 指标2 | 0.2 | … | … |
| 指标3 | 0.3 | … | … |
| 指标4 | 0.4 | … | … |
| 指标5 | 0.5 | … | … |
s=0.1x0.1+0.2x0.2+0.3x0.3+0.4x0.4+0.5x0.5
11. 计算前 个主成分的权重
基于方差贡献率占前 个主成分方差贡献率之和的比值得到权重:
其中 是第 个主成分的方差贡献率。
例子:主成分分析结果
| 特征值 | 方差贡献率 | 累计方差贡献率 |
|---|---|---|
| 3 | 44% | 44% |
| 2 | 30% | 74% |
| 1 | 15% | 89% |
| 0.5 | 7% | 96% |
| 0.25 | 4% | 100% |
主成分的权重计算(只选择前3个主成分)
- 第一主成分:
- 第二主成分:
- 第三主成分:
12. 计算指标权重
注意: 一般情况下主成分分析计算权重和计算综合得分是两种方法,根据你的需要写入论文,即你用主成分分析计算指标权重就使用第 12 步的公式,使用主成分分析计算综合得分就使用第 13 步的公式。(不过我觉得有指标权重可以更好解释对象综合得分的结果)
指标权重=主成分权重与主成分系数(特征向量)对应相乘求和
公式:
对指标的综合得分归一化,得到指标权重:
例子:
| 指标 | 主成分1 | 主成分2 | 主成分3 |
|---|---|---|---|
| 指标1 | 0.3 | 0.2 | 0.1 |
| 指标2 | … | … | … |
| 指标3 | … | … | … |
| 指标4 | … | … | … |
| 指标5 | … | … | … |
第1、2、3主成分的权重分别为:0.49、0.34、0.17,则指标1的综合得分系数为:
计算出所有指标的综合得分系数之后,归一化得到指标权重:
13. 计算对象综合得分
对象综合得分=主成分权重与主成分得分对应相乘求和
公式:
例子:
假设对象A在主成分1、2、3下的得分分别为0.3、0.2、0.1,主成分1、2、3的权重分别为0.49, 0.34, 0.17,则对象A的综合得分为:
最终对象综合得分和排序表示如下:
| 对象 | 主成分1得分 | 主成分2得分 | 主成分3得分 | 综合得分 | 排序 |
|---|---|---|---|---|---|
| A | 0.3 | 0.2 | 0.1 | 0.232 | 1 |
| B | … | … | … | 0.22 | 2 |
| C | … | … | … | 0.21 | 3 |
| D | … | … | … | 0.20 | 4 |
| E | … | … | … | 0.19 | 5 |
| F | … | … | … | 0.18 | 6 |
| G | … | … | … | 0.17 | 7 |
代码实现
示例数据:主成分分析示例文件.xlsx
输出结果

matlab实现
代码功能
-
支持三种方法选择主成分个数
- 根据特征值
- 根据累计方差贡献率
- 手动设置主成分个数
-
输出
- KMO 和 Bartlett 检验表:包含 “KMO 值”“Bartlett 球形检验 - 卡方值”“Bartlett 球形检验 - 自由度”“Bartlett 球形检验 - p 值” 等行名对应的检验结果数据,详细记录了数据适用性检验的各项指标情况。
- 标准化矩阵表:展示经过 Z-Score 标准化处理后的数据,包含样本名(若有读取行名)以及各变量对应的标准化数值,用于后续查看数据标准化后的状态。
- 相关系数矩阵表:呈现数据标准化后的相关系数矩阵,行列名与原数据变量名一致(添加了合适的表头处理),反映各变量间的相关关系情况。
- 方差解释表:有 “成分编号”“特征根”“方差解释率 (%)”“累计方差解释率 (%)” 等列,清晰列出各主成分在解释数据方差方面的相关指标,辅助确定主成分的重要性及数量选择等。
- 载荷系数矩阵表:包含特征名、各主成分(带有方差解释率后缀,如
PC1(XX%))对应的载荷系数以及 “共同度(公因子方差)” 等内容,展示主成分与原始变量间的载荷关系及共同度情况。 - 特征向量矩表:以特征名为行名,各主成分(带方差解释率后缀)为列名,展示特征向量相关数据,体现主成分分析中特征向量的构成情况。
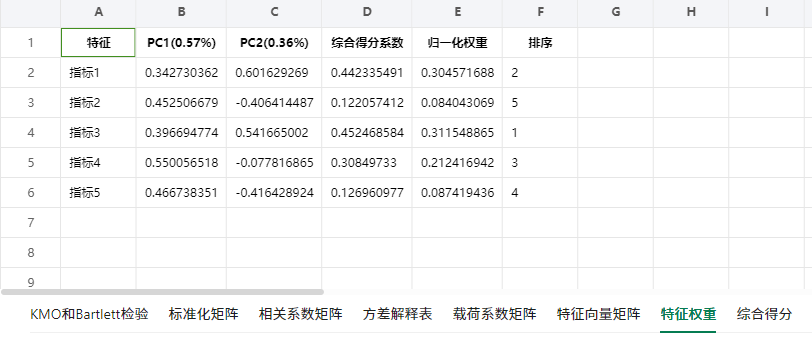
- 特征权重表:涵盖特征名、各主成分(带方差解释率后缀)对应的相关系数、“综合得分系数”“归一化权重”“排序” 等列,用于呈现各特征在综合评价中的权重相关信息。
- 综合得分表:展示样本名、各主成分(带方差解释率后缀)的得分、“综合得分” 以及 “排序” 等内容,呈现各样本基于主成分分析得出的综合得分及相应排序情况。
1 | pca_analysis("主成分分析示例文件.xlsx", 'isReadRowNames', true, 'method', 'variance', 'threshold', 0.7) |
python实现
1 | import pandas as pd |
相关考试题目
降维后两个主成分线性关系为
方差贡献率为 , 方差贡献率为 ,请通过主成分分析确定 的值,结果用含字母表达式表示,不需要归一化处理。
解答:
某个变量在综合得分模型中的系数 = (该变量在第一主成分中的系数 ***** 第一主成分的方差贡献率 + 该变量在第二主成分中的系数 ***** 第二主成分的方差贡献率) / (第一主成分的方差贡献率 + 第二主成分的方差贡献率)
将这个逻辑应用到我们的问题中,我们可以得到以下公式(由于不需要归一化):